Machines That Learn Like Us: Unraveling the Generalization-Memorization Puzzle
Written on
Understanding the Generalization-Memorization Dilemma
The ultimate goal in Machine Learning is to create systems capable of both memorizing established patterns from training data and generalizing to unfamiliar patterns encountered in real-world situations. This dual ability mirrors human learning; for instance, you can recognize your grandmother in an old photograph and identify a Xoloitzcuintli as a dog even without prior exposure. Without memorization, we would be forced to relearn everything, and without generalization, adapting to a dynamic environment would be impossible. Thus, both capabilities are essential for survival.
Traditional statistical learning theories suggest that achieving both is unattainable: models can either excel at generalization or memorization, but not both. This concept is known as the bias-variance trade-off, a fundamental principle in standard Machine Learning courses.
So, how can we construct such versatile learning systems? Is this “holy grail” truly within our reach? In this article, we will explore three key paradigms from existing literature:
- Generalize first, memorize later
- Generalize and memorize simultaneously
- Generalize with machines, memorize with humans
Let’s delve in.
Generalize First, Memorize Later
The introduction of the pre-training and fine-tuning paradigm by BERT has significantly transformed Machine Learning. After undergoing unsupervised pre-training on vast amounts of text data, the model can be quickly fine-tuned for specific downstream tasks with fewer labeled examples.
Surprisingly, this pre-training/fine-tuning strategy addresses the generalization-memorization dilemma effectively. Research conducted by Michael Tänzer and colleagues at Imperial College London in 2022 reveals that BERT can both generalize and memorize.
During fine-tuning, BERT appears to learn in three distinct stages: - Fitting (Epoch 1): The model identifies basic, universal patterns that capture as much training data as possible, resulting in improved training and validation performance. - Setting (Epochs 2-5): With no more simple patterns to grasp, training and validation performance levels off, creating a plateau in the learning curve. - Memorization (Epochs 6+): The model begins to memorize specific training examples, including noise, leading to enhanced training performance but diminished validation results.
This observation emerged from starting with a clean training dataset (CoNLL03, a benchmark dataset for named-entity recognition) and gradually introducing artificial label noise. Analyzing the learning curves with varying noise levels made the three distinct phases clear: increased noise correlates with a more pronounced decline in phase three.
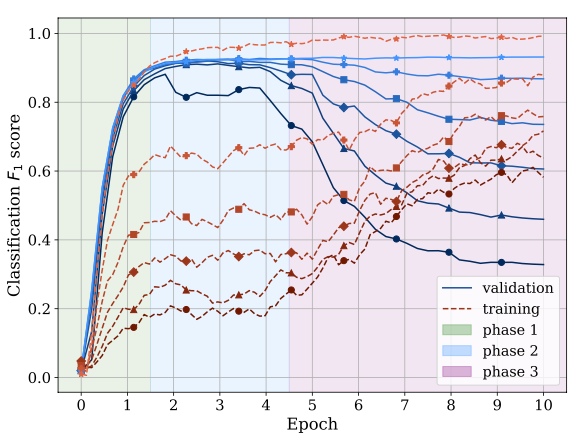
Tänzer et al. also found that memorization in BERT necessitates repetition; BERT retains a specific training example only after encountering it multiple times. This is evident from the learning curve with added noise, which resembles a step function that improves with each epoch. Consequently, BERT can eventually memorize the entire training set with sufficient training epochs.
In summary, BERT showcases the capacity to generalize initially and memorize subsequently, demonstrated through its three distinct learning phases during fine-tuning. Notably, a randomly initialized BERT model does not exhibit the same learning phases, suggesting that the pre-training/fine-tuning paradigm may provide a viable solution to the generalization-memorization conundrum.
This video delves into quantifying and comprehending memorization in deep neural networks, further elucidating BERT's learning mechanisms.
Generalize and Memorize Simultaneously
Transitioning from natural language processing to recommender systems, the simultaneous ability to memorize and generalize is crucial. For instance, YouTube aims to present videos similar to those you've previously watched (memorization) while also introducing new recommendations that align with your interests (generalization). A lack of memorization leads to frustration, while insufficient generalization results in boredom.
Modern recommender systems must achieve both capabilities. In a 2016 study, Heng-Tze Cheng and collaborators from Google introduced the “Wide and Deep Learning” framework to tackle this challenge. The innovative concept involves creating a unified neural network with both a deep component (a deep neural net with embedded inputs) for generalization and a wide component (a linear model with numerous sparse inputs) for memorization.
The deep component processes dense features and categorical feature embeddings, such as user language and installed apps. These embeddings are initialized randomly and fine-tuned during model training alongside other neural network parameters. Conversely, the wide component utilizes detailed cross-features, such as “AND(user_installed_app=netflix, impression_app=hulu),” which evaluates to 1 if a user has Netflix installed and the impressed app is Hulu.
The wide component plays a key role in memorization; it captures critical patterns that may be overlooked by the deep component. Cheng et al. argue that integrating both components is vital for optimal performance.
Experimental results corroborate their hypothesis, revealing that the wide and deep model outperformed both the wide-only (by 2.9%) and deep-only models (by 1%) in terms of online acquisition in the Google Play Store. Thus, the “Wide & Deep” paradigm emerges as another promising strategy to address the generalization-memorization dilemma.
This video discusses building machines that learn and think like humans, providing insight into the principles behind recommender systems.
Generalize with Machines, Memorize with Humans
While both Tänzer and Cheng proposed machine-centric solutions to the generalization-memorization challenge, machines often struggle to memorize singular instances. For example, Tänzer et al. found that BERT needs at least 25 examples of a class to learn to recognize it and 100 to predict it with reasonable accuracy.
Instead of relying solely on machines, why not leverage human expertise? This concept is the foundation of Chimera, a production system developed by Walmart for large-scale e-commerce item classification, as presented in a 2014 study by Chong Sun and collaborators from Walmart Labs. The core idea behind Chimera is that Machine Learning alone cannot effectively manage item classification at scale due to numerous edge cases with limited training data.
For instance, Walmart may trial a limited number of new products from a vendor. An ML system might struggle to accurately classify these items due to insufficient training data. However, human analysts can create rules to address these specific cases. These rule-based decisions can later inform model training, allowing the model to adapt to new patterns over time.
The authors conclude: “We utilize both machine learning and handcrafted rules extensively. Rules in our system are not merely supplementary; they are crucial for achieving the desired performance and provide domain analysts with a rapid and effective method to contribute feedback into the system. To our knowledge, we are the first to outline an industrial-strength system where both [Machine] learning and rules coexist as primary elements.”
Ultimately, this coexistence may be pivotal in resolving the generalization-memorization challenge.
Coda: Systems That Learn Like Us
To summarize, developing systems capable of memorizing established patterns and generalizing to new ones is the holy grail of Machine Learning. Although the problem remains unresolved, we have identified several promising approaches:
- BERT has demonstrated the ability to generalize first and memorize later during fine-tuning, enabled by prior pre-training.
- Wide & Deep neural networks have been created to generalize (through the deep component) and memorize (via the wide component) simultaneously, outperforming both wide-only and deep-only models in Google Play store recommendations.
- Walmart’s Chimera system combines human expertise to formulate rules for edge cases that their ML models struggle to memorize. By integrating these rule-based decisions back into the training data, the ML models can adapt over time, allowing both ML and rules to coexist as primary elements.
This exploration is just a glimpse of the vast landscape of solutions. Any industrial ML team must confront some iteration of the memorization/generalization dilemma, and if you work in ML, you are likely to encounter it eventually.
Ultimately, addressing this issue will not only enable us to create superior ML systems but also help us develop systems that learn more like humans.