Understanding the Fundamentals of Reinforcement Learning
Written on
Chapter 1: Overview of Reinforcement Learning
Reinforcement learning focuses on quantifying the probability of transitioning from a state (s) to an action (a) and then to a new state (s?). The primary objective is for the algorithm to develop an optimal policy, enabling it to make the best possible action based on the current state. Over time, actions that yield favorable results are reinforced, while those that lead to undesirable outcomes are discouraged.
Optimal Policy
An optimal policy is designed to maximize the average reward over time. It must consider both immediate outcomes and associated costs. Additionally, it adopts a non-myopic approach, weighing near-term effects more heavily than those of the distant future.
Reinforcement Learning Setup
To effectively model the current state, we discretize each continuous value into n bins.
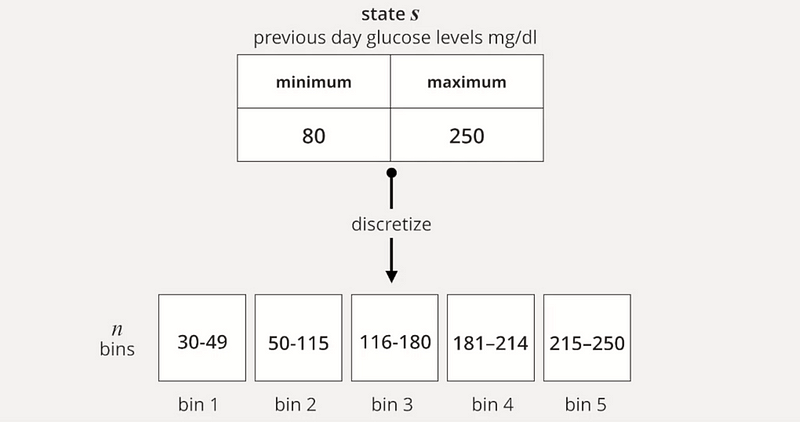
This discretization process is also applied to actions.
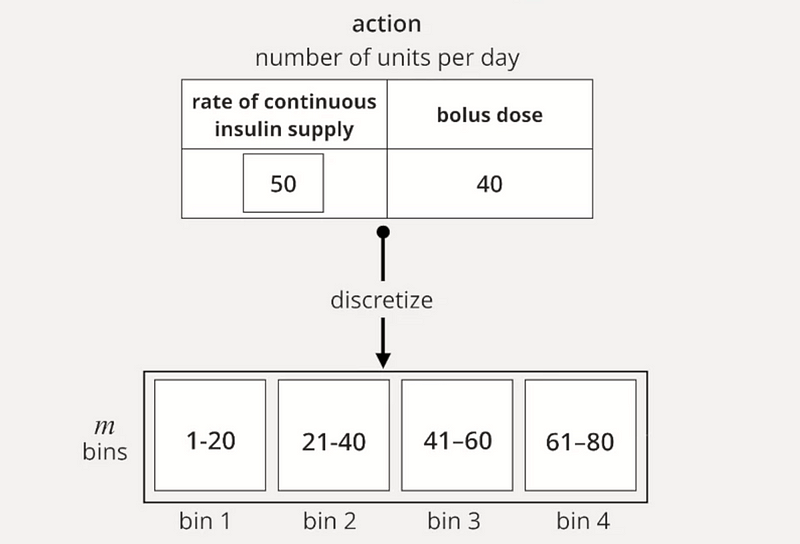
As a result, we create a state-action matrix and establish a function known as the Q Function, which represents the value of taking action (a) in state (s). The aim of reinforcement learning is to accurately learn this Q Function to gauge the reward associated with actions taken in various states.
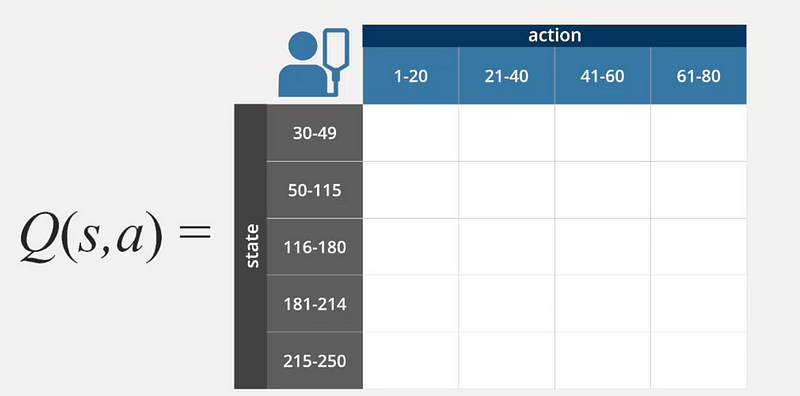
Solving the Q Function
To solve for the Q Function, we start by initializing the Q table either with known state and action values or randomly. The next step involves selecting an action and observing the resulting reward. Based on this feedback, we update the Q table accordingly.
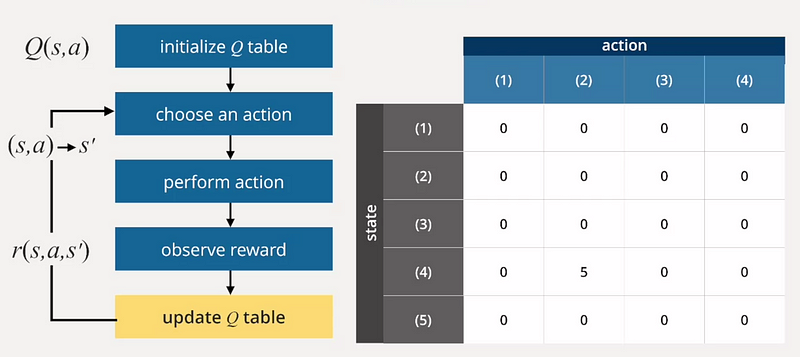
The Q Table is then modified based on the difference between the received reward and the previous Q-function value. If the reward (r) exceeds the old Q-function value, we increase the action's value for the new Q-function; otherwise, we decrease it.
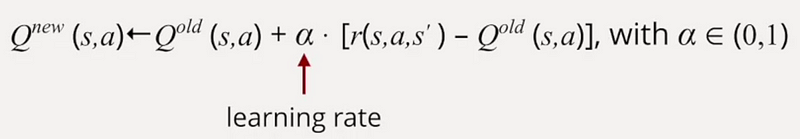
The learning rate (a) is a crucial parameter that adjusts the Q-function value based on observations, with values ranging between 0 and 1.
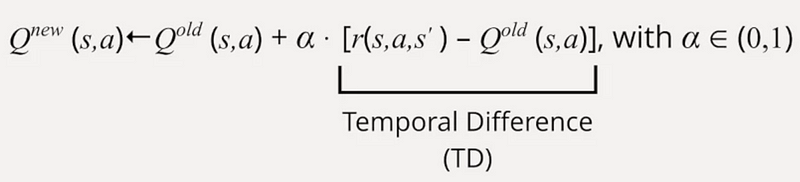
Temporal Difference in Q Learning
The temporal difference method compares the immediate reward (r) with the old Q-function value derived from taking action (a) in state (s). A positive temporal difference indicates that the immediate reward is greater than previously estimated, suggesting that the value of taking action (a) in state (s) is underestimated. Consequently, we increase the value of that action in the Q table.
Limitations of the Q Function
One significant limitation of the Q Function is its focus solely on predicting immediate rewards (r), neglecting potential future scenarios. To address this, it must be expanded to consider both immediate rewards and long-term outcomes, promoting a non-myopic policy.
Curious about learning more? Discover the extensive range of topics available on Medium and support writers like me for the price of a coffee!