OpenAI Foundry: Revolutionizing Large-Scale Inference Platforms
Written on
Chapter 1: Introduction to OpenAI Foundry
OpenAI is preparing to unveil a new product named Foundry, which serves as a specialized platform for executing OpenAI models. This initiative is tailored for clients with sophisticated requirements and substantial workloads. Foundry empowers users to conduct large-scale inference while maintaining comprehensive control over model configurations and performance metrics. By utilizing this platform, clients can harness dedicated resources to optimize throughput, latency, and costs tailored to their unique needs.
Chapter 2: Features of Foundry
Currently, Foundry facilitates large-scale inference through a fixed allocation of resources, exclusively dedicated to users. This design fosters a predictable environment under the users' control. With access to the same monitoring tools and dashboards as OpenAI, users can oversee their individual instances and refine shared capacity models, thereby achieving optimal performance in terms of throughput, latency, and costs. Furthermore, users have the flexibility to choose their model snapshot, deciding whether to utilize the latest version available.
The first video titled "OpenAI's MEMETIC warfare... GPT-4o LARGE" explores the implications of large context windows in AI models, enhancing understanding of the latest advancements in AI technology.
Chapter 3: Future Developments and Pricing
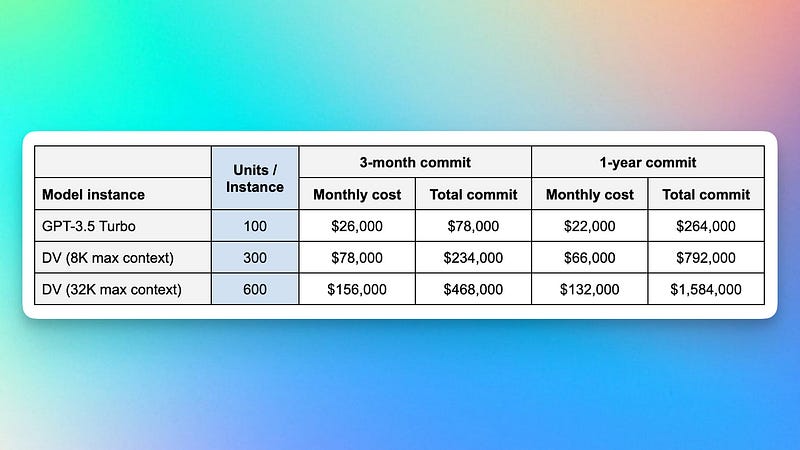
In the upcoming months, OpenAI plans to provide enhanced fine-tuning options for its latest models, with Foundry being the primary platform for deploying these advancements. Additionally, Foundry guarantees Service Level Agreements (SLAs) for instance uptime, along with on-call engineering support, promising 99.5% uptime. The rental model for Foundry is based on dedicated compute units, offering 3-month or 1-year commitments with a 15% discount available. For details on the number of compute units necessary for operating a particular model instance, refer to the image above.
The second video "Behind the scenes scaling ChatGPT - Evan Morikawa at LeadDev West Coast 2023" provides insights into the scaling challenges faced by ChatGPT, elaborating on the engineering efforts behind its development.
Chapter 4: Anticipating GPT-4
The pricing chart for the instance types available from OpenAI has piqued the interest of many users online. Notably, among the models listed is one featuring a maximum context window of 32k tokens, indicating the amount of text the model processes before generating further text. This represents a significant enhancement compared to OpenAI’s most recent text generation model, GPT-3.5, which is limited to a 4k context window. The emergence of this enigmatic new model with such an expansive context window has sparked speculation that it could be the eagerly awaited GPT-4 or an early iteration of it.
Chapter 5: Conclusion
In light of Microsoft's substantial investment in OpenAI, the company faces increased expectations for profitability. To meet these demands, OpenAI has introduced ChatGPT Plus and the Foundry platform, both aimed at generating revenue through dedicated capacity for running OpenAI models. The success of these initiatives remains uncertain, posing questions about their effectiveness in achieving OpenAI’s financial goals.